ABabyChal 指的是运行 Ark 引擎 (Ark JavaScript VM) 来执行一个 编译好的字节码文件 chal.abc 。
.abc 文件是 Ark ByteCode (方舟字节码)文件。arkcompile 或 es2abc 工具生成的中间格式。
Disassembler是ArkTS反汇编工具。如果需要分析方舟字节码文件(*.abc)相关问题,开发者可以使用Disassembler将方舟字节码文件反编译为可读的汇编指令。
工具随DevEco Studio SDK发布。以Windows平台为例,Disassembler工具位于DevEco Studio/sdk/default/openharmony/toolchains/ark_disasm.exe。
报错了,换一个工具:jadx-dev-all.jar,读取abc文件的jdax工具。
方舟字节码文件格式:
字节码文件起始于Header 结构。文件中的所有结构均可以从Header出发,直接或间接地访问到。字节码文件中所有的多字节值均采用小端字节序。
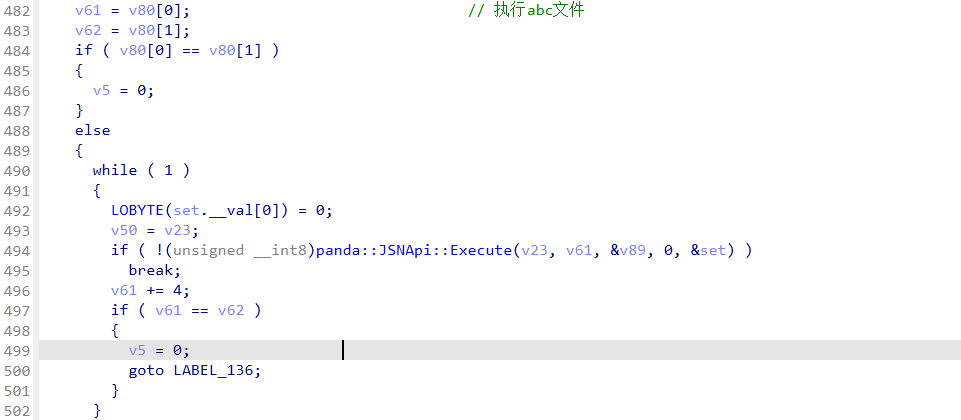
执行abc文件:
v80 是一个 std::vector<std::string> 的底层数组,存储分割后的 ABC 文件路径(或者入口函数信息)。
循环调用:panda::JSNApi::Execute(EcmaVM, path, &entry, 0, &set)
参数解释:
EcmaVM:VM 实例path:ABC 文件路径entry:入口函数名(可以是默认 main 或者用户指定)0:执行选项&set:可能是执行上下文或返回值存储
作用: 把 .abc 文件加载到 VM 并执行。
用jadx-dev-all.jar打开.abc文件有大量报错,猜测修改了字节码。搜索找到一份字节码表: harmony 鸿蒙Ark Bytecode Fundamentals
或者搜索⼀圈后找到函数 panda::ecmascript::RuntimeStubs::DebugPrintInstruction
尝试在libark_jsruntime.so中搜索一个字节码名称,还真能找到:
根据这个字节码找到修改后的字节码表函数sub_1F73E90:
1 2 3 4 5 6 7 8 9 __int64 __fastcall sub_1F73E90(__int64 a1, unsigned __int8 **a2) { int v3; // eax char *v4; // rsi const char *v5; // rsi const char *v6; // rsi const char *v7; // rsi const char *v8; // rsi const char *v9; // rsi
根据这个函数修复.abc文件中的字节码,得到的out.abc可以使用刚才的工具反编译。
validateChallenge 的处理管线(正向)大致是:
把用户输入当作 Base64 解码(definefunc2)。
用一个替换表对字符做简单替换(createobjectwithbuffer)。
对字母/数字做逐位可变的 Caesar 位移(每位不同的偏移 (i*17+23)%26)。
对每字节做按位循环左移(移位量依赖于状态机 i7/i8)。
将结果每 6 字节一组反转(reverse 每 6 字符块)。
把字符串用 3 个不同的字节数组作为循环 key 做三轮 xor(每轮:(byte ^ key[(i*11)%len(key)]) ^ ((i*3)&255))。
再按一个固定的索引置换(permutation array)抽取出最终的字节序列 r42,并对其做 Base64 编码后与常量字符串比较。
得到的结果大部分正确,最后两字节有问题,根据题目提示md5爆⼀下即可。
1 2 3 4 5 6 7 8 s = b'flag{4f9cc0d2b33f5d7e2b0955765bb33f0' from hashlib import md5 for i in '0123456789abcdef': if md5(s + i.encode() + b'}').hexdigest() == '7a2028696ca643a57ddeda6642f781ae': print(s + i.encode() + b'}') # flag{4f9cc0d2b33f5d7e2b0955765bb33f0a}
butterfly 核心编码逻辑在MMX部分
1 2 3 v29 = _m_pxor(v28->m64_u64, v42[0]); // XOR v30 = _m_por(_m_psrlwi(v29, 8u), _m_psllwi(v29, 8u)); // 字节交换 v28->m64_u64 = _m_paddb(_m_por(_m_psllqi(v30, 1u), _m_psrlqi(v30, 0x3Fu)), v42[0]); // 循环移位+加法
逆这个过程
密钥信息:
1 v24 = _mm_loadu_si128((const __m128i *)"MMXEncode2024");
程序会生成:
1 2 3 4 5 encoded.dat:8F A3 9C B7 70 8D 8F 98 9D BF 8C 99 8C 73 E5 90 8D 8D 8C 85 88 79 85 7C 9D 9F 3C 53 16 15 19 12 36 37 7D 0A encoded.dat.key:4D 4D 58 45 6E 63 6F 64 65 32 30 32 34 00 45 6E 63 6F 64 69 6E 67 20 66 69 6C 65 3A 20 25 73 0A
encoded.dat.key :4D 4D 58 45 6E 63 6F 64 65 32 30 32 34 = "MMXEncode2024"
从代码看,编码步骤是:
_m_pxor - XOR操作_m_por(_m_psrlwi(v29, 8u), _m_psllwi(v29, 8u)) - 字节交换_m_por(_m_psllqi(v30, 1u), _m_psrlqi(v30, 0x3Fu)) - 循环左移1位_m_paddb - 字节加法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 def mmx_decode_precise(encoded_data, key): key_bytes = key.ljust(8, b'\x00')[:8] # 取前8字节作为XOR密钥 key_qword = int.from_bytes(key_bytes, 'little') decoded = bytearray() for i in range(0, len(encoded_data), 8): chunk = encoded_data[i:i+8] if len(chunk) < 8: chunk = chunk + b'\x00' * (8 - len(chunk)) encrypted = int.from_bytes(chunk, 'little') # 逆向 _m_paddb temp1 = encrypted temp1_bytes = bytearray() for j in range(8): byte_val = (temp1 >> (j * 8)) & 0xFF # 减去key的对应字节 key_byte = (key_qword >> (j * 8)) & 0xFF temp1_bytes.append((byte_val - key_byte) & 0xFF) temp1 = int.from_bytes(temp1_bytes, 'little') # 逆向循环移位: 右移1位 (原先是左移1位) temp2 = ((temp1 >> 1) | ((temp1 & 1) << 63)) & 0xFFFFFFFFFFFFFFFF # 逆向字节交换 (16位字内交换字节) temp3_bytes = bytearray() temp2_bytes = temp2.to_bytes(8, 'little') for j in range(0, 8, 2): if j + 1 < 8: temp3_bytes.append(temp2_bytes[j + 1]) temp3_bytes.append(temp2_bytes[j]) else: temp3_bytes.append(temp2_bytes[j]) temp3 = int.from_bytes(temp3_bytes, 'little') # XOR解密 decrypted = temp3 ^ key_qword decrypted_bytes = decrypted.to_bytes(8, 'little') decoded.extend(decrypted_bytes[:min(8, len(encoded_data)-i)]) return bytes(decoded) # 编码的数据 encoded_hex = "8F A3 9C B7 70 8D 8F 98 9D BF 8C 99 8C 73 E5 90 8D 8D 8C 85 88 79 85 7C 9D 9F 3C 53 16 15 19 12 36 37 7D 0A" encoded_bytes = bytes.fromhex(encoded_hex.replace(" ", "")) # 密钥 key = b"MMXEncode2024" print(f"编码数据长度: {len(encoded_bytes)} 字节") print(f"密钥: {key}") # 解码 decoded_result = mmx_decode_precise(encoded_bytes, key) print("\n解码结果 (十六进制):", decoded_result.hex()) print("解码结果 (原始字节):", decoded_result) print("\n可读文本:", decoded_result.decode('utf-8', errors='ignore')) # 尝试不同的编码 try: print("作为ASCII:", decoded_result.decode('ascii', errors='ignore')) except: pass # 显示每个字节的值 print("\n字节分析:") for i, byte in enumerate(decoded_result): print(f"字节[{i:2d}]: 0x{byte:02X} = {byte:3d} = '{chr(byte) if 32 <= byte < 127 else '?'}'")
trade
docker desktop代理设置
1 2 3 4 5 6 7 8 9 10 11 12 13 { "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": false, "registry-mirrors": [ "https://docker.1ms.run", "https://docker.1panel.live/" ] }
动态调试:
1 2 3 ./tragre pgrep -fl tradre gdbserver :1234 --attach 8900